Impact of parallelism and processor architecture while building a kernel
Given that Bálint just braggedblogged about how
efficiently he can build a Linux
kernel
(less than 8 seconds, wow! Well, yes, until you read it is the
result of aggressive caching and is achieved only for a second run),
and that a question just popped up today on the Debian ARM mailing
list, «is an ARM computer a good choice? Which
one?»,
I decided to share my results of an experiment I did several months
ago, to graphically show to my students the effects of parallelism,
the artifacts of hyperthreading, the effects of different architecture
sets, and even illustrate about the actual futility of my experiment
(somewhat referring to John Gustafson’s reevaluation of Amdahl’s
law, already 30 years
ago — «One does
not take a fixed-size problem and run it on various numbers of
processors except when doing academic research»; thanks for referring
to my inconsequential reiterative compilations as academic research! 😉)
I don’t expect any of the following images to be groundbreaking, but at least, next time I need to find them it is quite likely I’ll be able to find them — and I will be able to more easily refer to them in online discussions 😉

So… What did I do? I compiled Linux repeatedly, on several of the
machines I had available, varying the -j flag (how many cores to use
simultaneously), starting with single-core, and pushing up until just
a bit over the physical number of cores the CPU has.
Sadly, I lost several of my output images, but the three following are enough to tell interesting bits of the story:
-
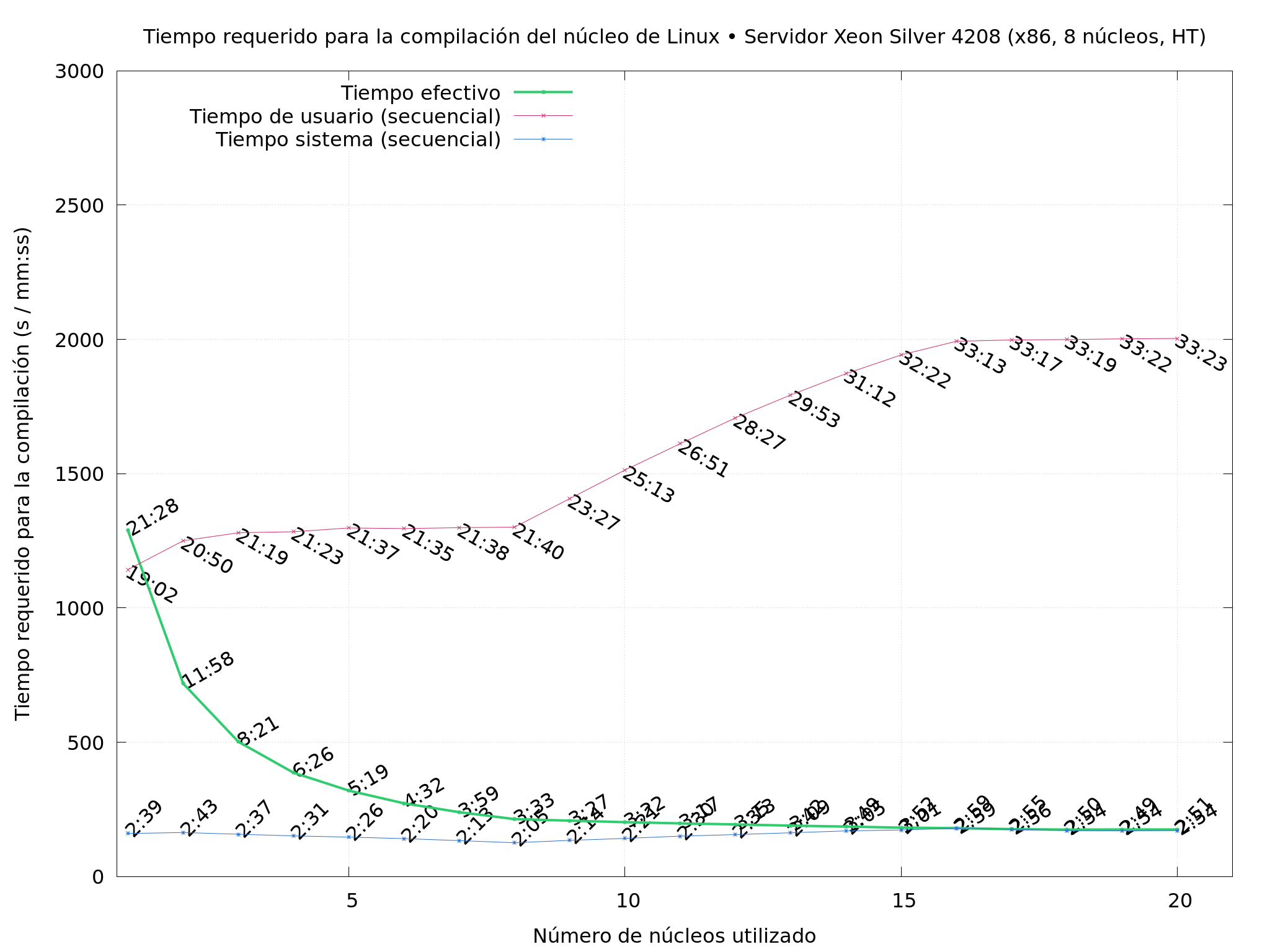
A nice little server my Institute acquired in early 2021: Xeon Silver 4208, with 8 physical cores (plus hyperthreading)
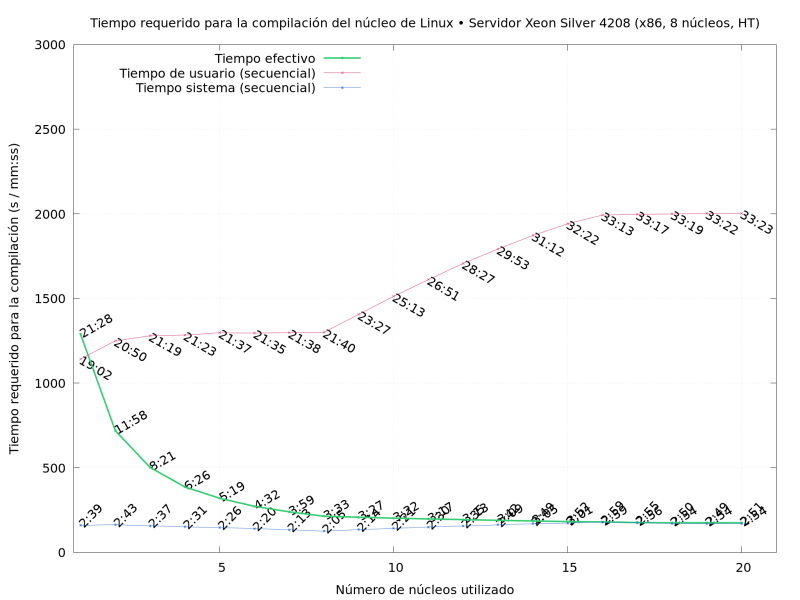
-
My laptop, an 8-ARM-core Lenovo Yoga C630. Do note it’s a “big.LITTLE” system, where 4 cores are smaller and 4 are bigger.
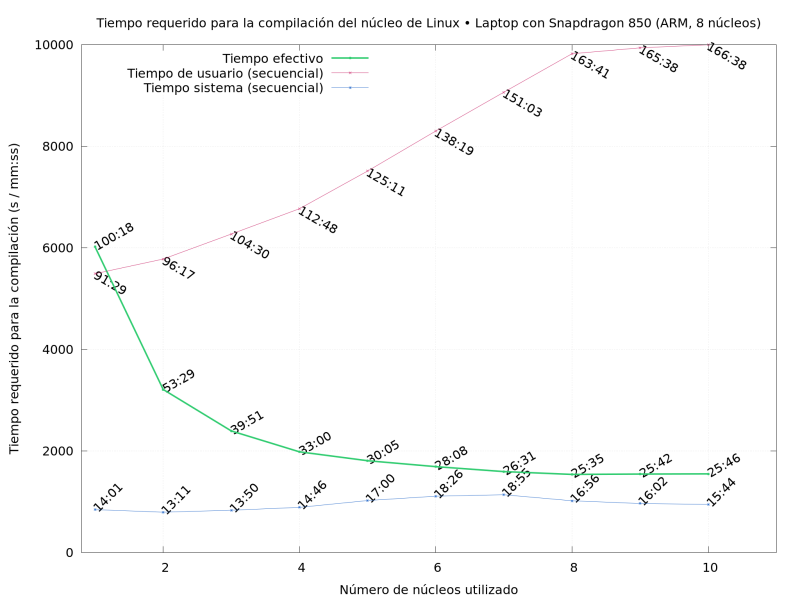
-
A Raspberry Pi 4 (8GB version)
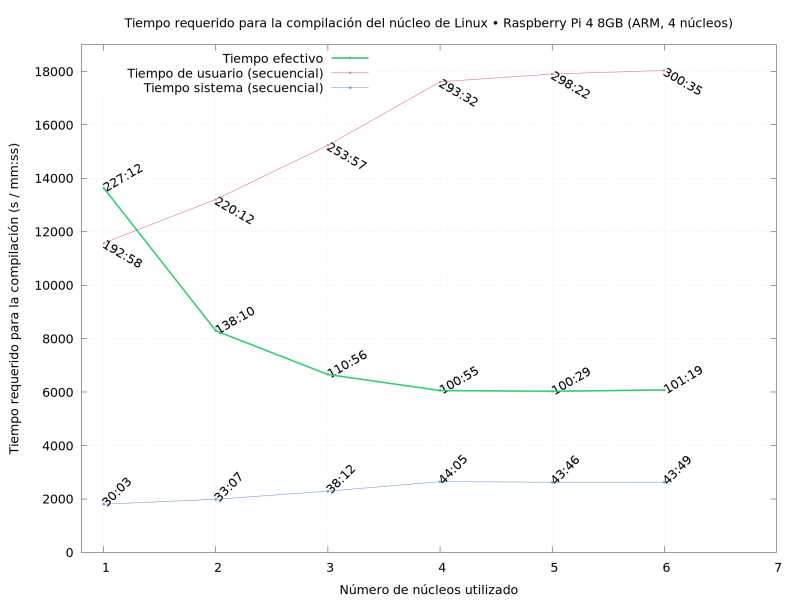
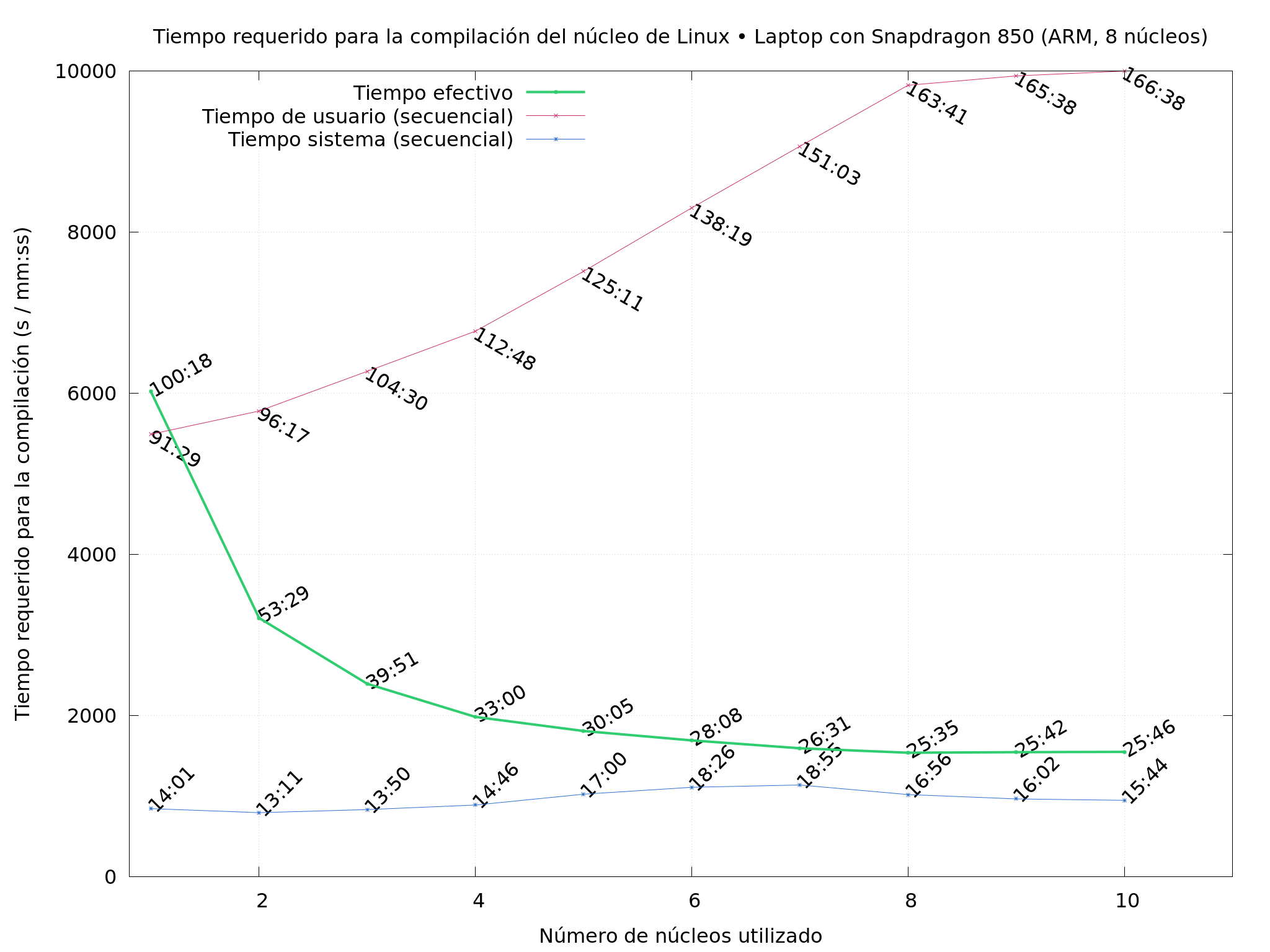
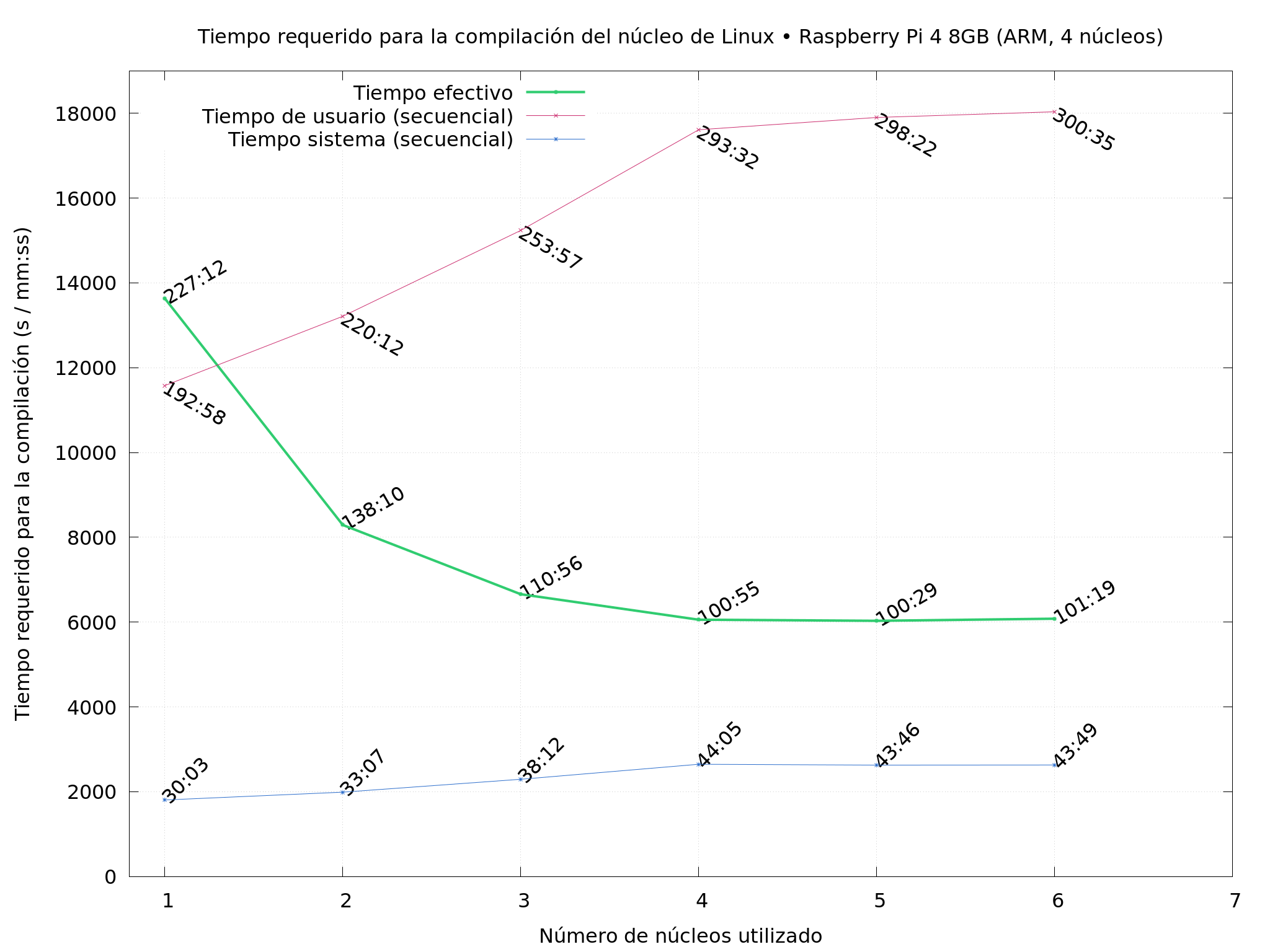
Of course, I have to add that this is not a scientific comparison; the server and my laptop have much better I/O than the Raspberry’s puny micro-SD card (and compiling hundreds of thousands of files is quite an IO-stressed job, even though the full task does exhibit the very low compared single-threaded performance of the Raspberry even compared with the Yoga).
No optimizations were done (they would be harmful to the effects I wanted to show!), the compile was made straight from the upstream sources.