LLM Hallucinations in Practical Code Generation — Phenomena, Mechanism, and Mitigation

- Media
- article
- Title
- LLM Hallucinations in Practical Code Generation — Phenomena, Mechanism, and Mitigation
- Author
- Ziyao Zhang, Chong Wang, Yanlin Wang, Ensheng Shi, Yuchi Ma, Wanjun Zhong, Jiachi Chen, Mingzhi Mao, Zibin Zheng
- Review published as
- 148040
- Edited by
- Proceedings of the ACM on Software Engineering, Volume 2, Issue ISSTA
How good can large language models (LLMs) be at generating code? This may not seem like a very novel question, as several benchmarks (for example, HumanEval and MBPP, published in 2021) existed before LLMs burst into public view and started the current artificial intelligence (AI) “inflation.” However, as the paper’s authors point out, code generation is very seldom done as an isolated function, but instead must be deployed in a coherent fashion together with the rest of the project or repository it is meant to be integrated into. Today, several benchmarks (for example, CoderEval or EvoCodeBench) measure the functional correctness of LLM-generated code via test case pass rates.
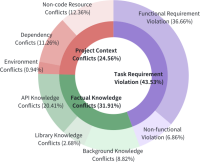
This paper brings a new proposal to the table: comparing LLM-generated repository-level evaluated code by examining the hallucinations generated. The authors begin by running the Python code generation tasks proposed in the CoderEval benchmark against six code-generating LLMs. Next, they analyze the results and build a taxonomy to describe code-based LLM hallucinations, with three types of conflicts (task requirement, factual knowledge, and project context) as first-level categories and eight subcategories within them. The authors then compare the results of each of the LLMs per the main hallucination category. Finally, they try to find the root cause for the hallucinations.
The paper is structured very clearly, not only presenting the three research questions (RQ) but also referring to them as needed to explain why and how each partial result is interpreted. RQ1 (establishing a hallucination taxonomy) is the most thoroughly explored. While RQ2 (LLM comparison) is clear, it just presents straightforward results without much analysis. RQ3 (root cause discussion) is undoubtedly interesting, but I feel it to be much more speculative and not directly related to the analysis performed.
After tackling their research questions, Zhang et al. propose a possible mitigation to counter the effect of hallucinations: enhance the LLM with retrieval-augmented generation (RAG) so it better understands task requirements, factual knowledge, and project context. The presented results show that all of the models are clearly (though modestly) improved by the proposed RAG-based mitigation.
The paper is clearly written and easy to read. It should provide its target audience with interesting insights and discussions. I would have liked more details on their RAG implementation, but I suppose that’s for a follow-up work.