About our proof-of-concept LLM tool for navigating Debian's manpages
So, for the first year, this year’s DebConf had the “DebConf Academic Track”, that is, content for a one-day-long set of short sessions, for which of them there was a written article presenting the content — often with a very academic format, but not necessarily. I hope that for future DebConfs we will continue to hold this track, and that we can help bridge the gap: to get people that are not usually from the academic / universitary prepare content that will be formally expressed and included in a long-lasting, indexed book of proceedings. We did have (informal) proceedings in many of the early DebConfs, and I’m very happy to regain that, but with 20 years of better practices.
Anyway, of course, I took the opportunity to join this experiment, and together with my Mexican colleague Tzolkin Garduño who is finishing her PhD here in France (or should I say, second to her, as she is the true leading author of our work). And here you can see the paper we submitted to the DebConf Academic Track, which will be published soon:
A retrieval-augmented-generation pipeline to help users query system-provided documentation
The corresponding source code is all available at Tzolkin’s repository in GitHub.
So, what is it about, in shorter words and layman terms?
Debian has lots of documentation, but lacks in discoverability. We targetted our venerable manpages: It is well known that manpages are relevant, well-organized documentation describing how to use each of the binaries we ship in Debian. Eric Raymond wrote in his well-known essay “The Art of Unix Programming” (2003) that the Unix cultural style is “telegraphic but complete. It does not hold you by the hand, but it usualy points in the right direction.”
Our original intent was to digest all of the information in our manpages, but we
narrowed it to only the first “section” of the manual due to the limitations of
the hardware a good friend lent us to play with LLMs. We took four different
base, redistributable (although, yes, non-DFSG-free) Large Language Models
downloaded from HuggingFace (T5-small, MiniLM-L6-v2, BGE-small-en and
Multilingual-e5-small), and trained them with the 34579 pages found inside
/usr/share/man/man1 of all of the existing Debian packages. We did some
interesting fine-tuning (for further details, please refer to the paper itself
or to our GitHub repository.
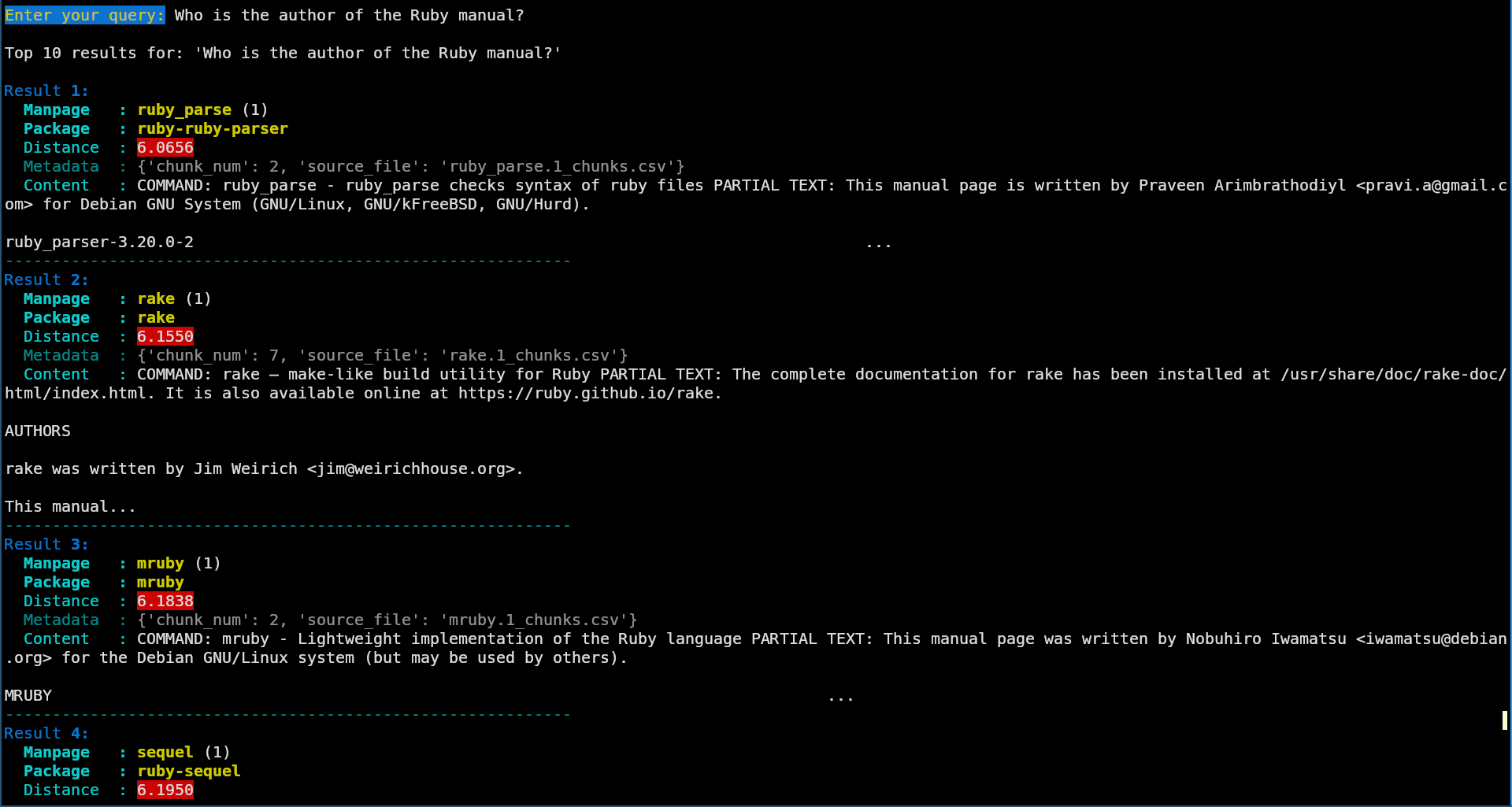
The idea is to present an interactive tool that udnerstand natural language queries, and answers with the specific manpage to which they better relate (I’d like to say “they answer best”, but Tzolkin has repeatedly tried to correct my understanding of the resulting vectorial distances).
I had prepared some images to present as interaction examples, but I’ll wrap up this post with something even better 😉 So, this is what you would get with the following queries:
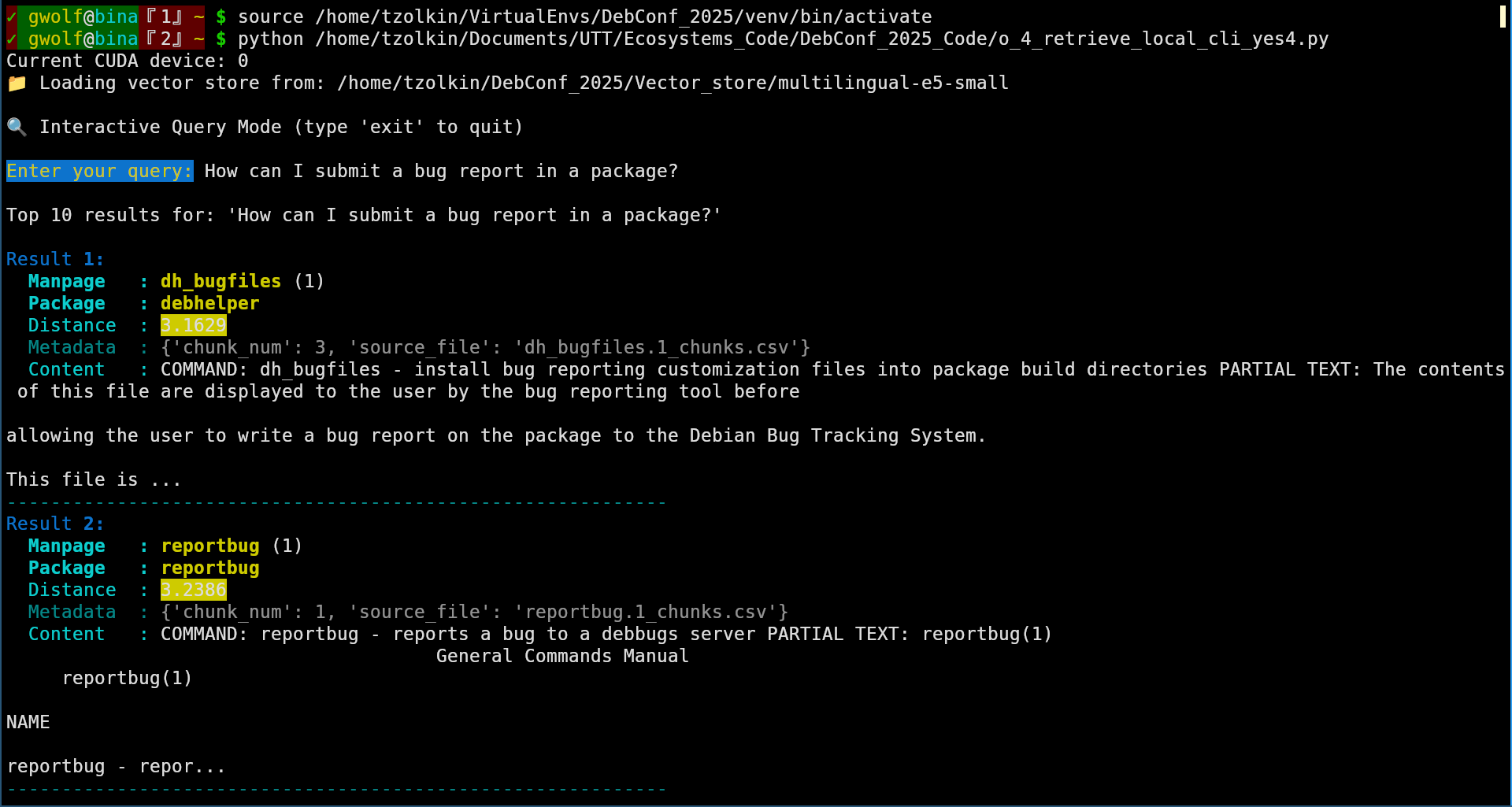
- How can I submit a bug report in a package?
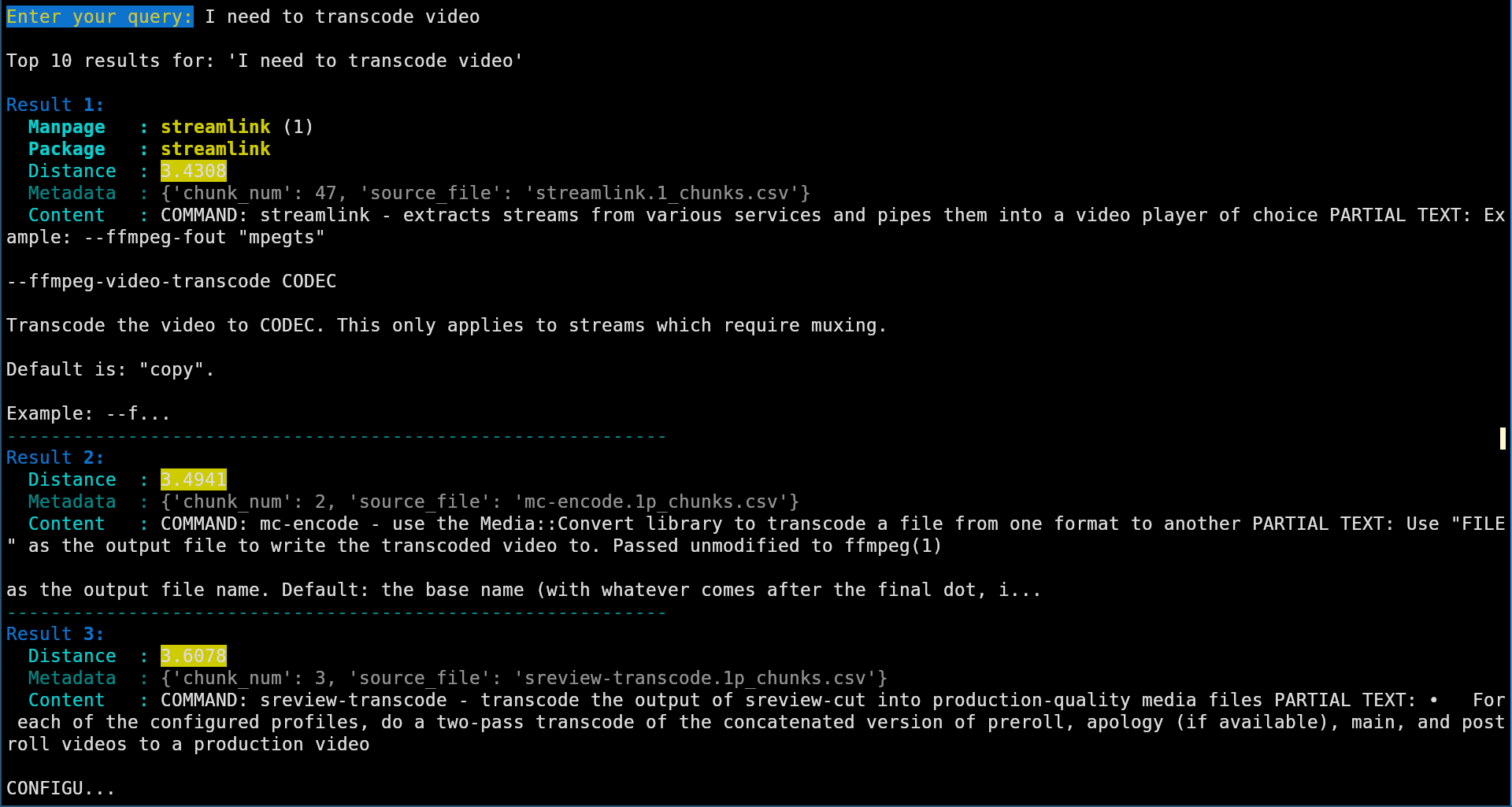
- I need to transcode video
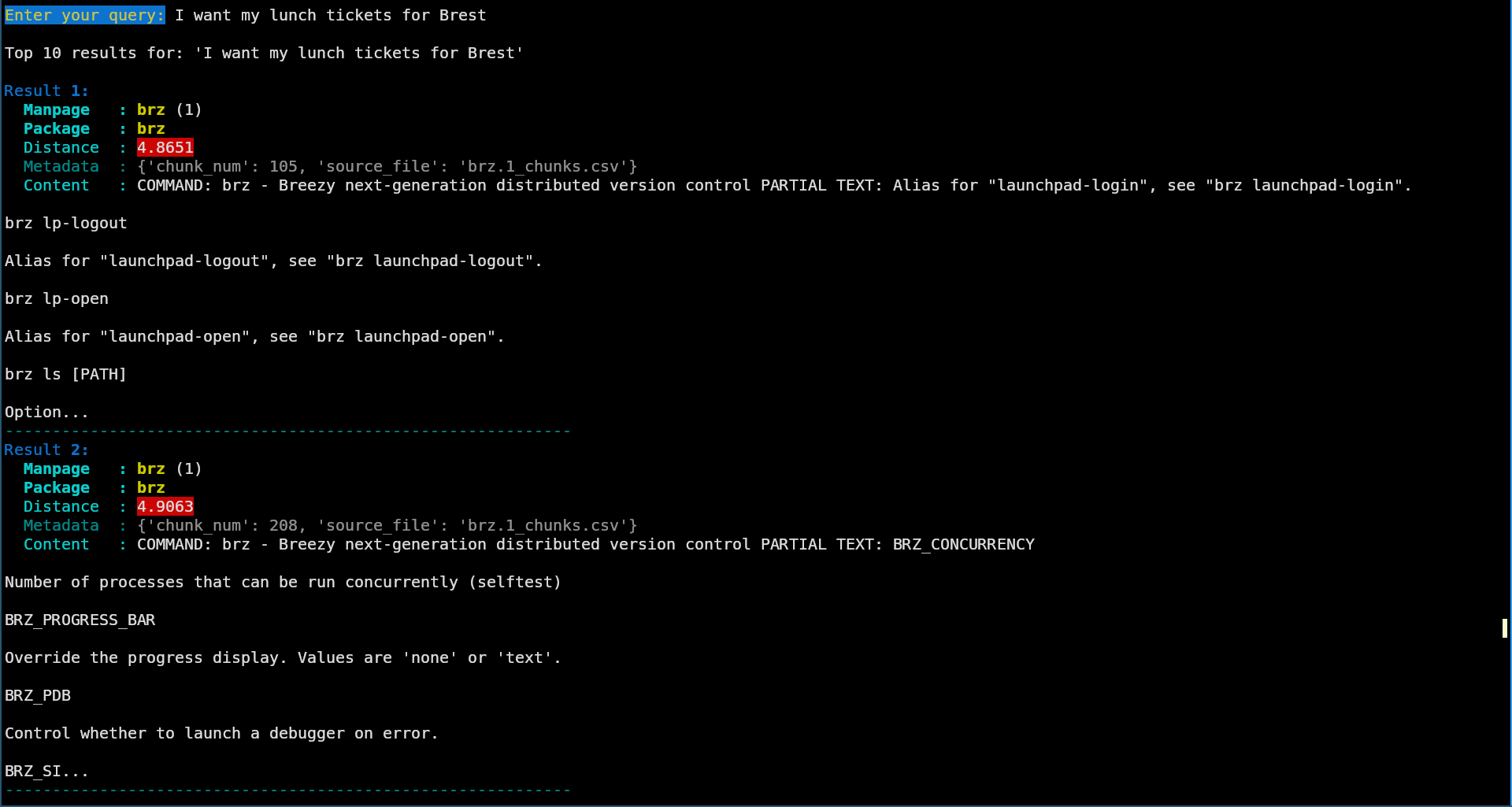
- Of course, garbage-in means garbage-out. LLMs cannot tell you “I don’t have an answer for you”, so you get hallucinations (or at least, irrelevant answers): I want my lunch tickets for Brest. Guess I was hungry when working my examples…
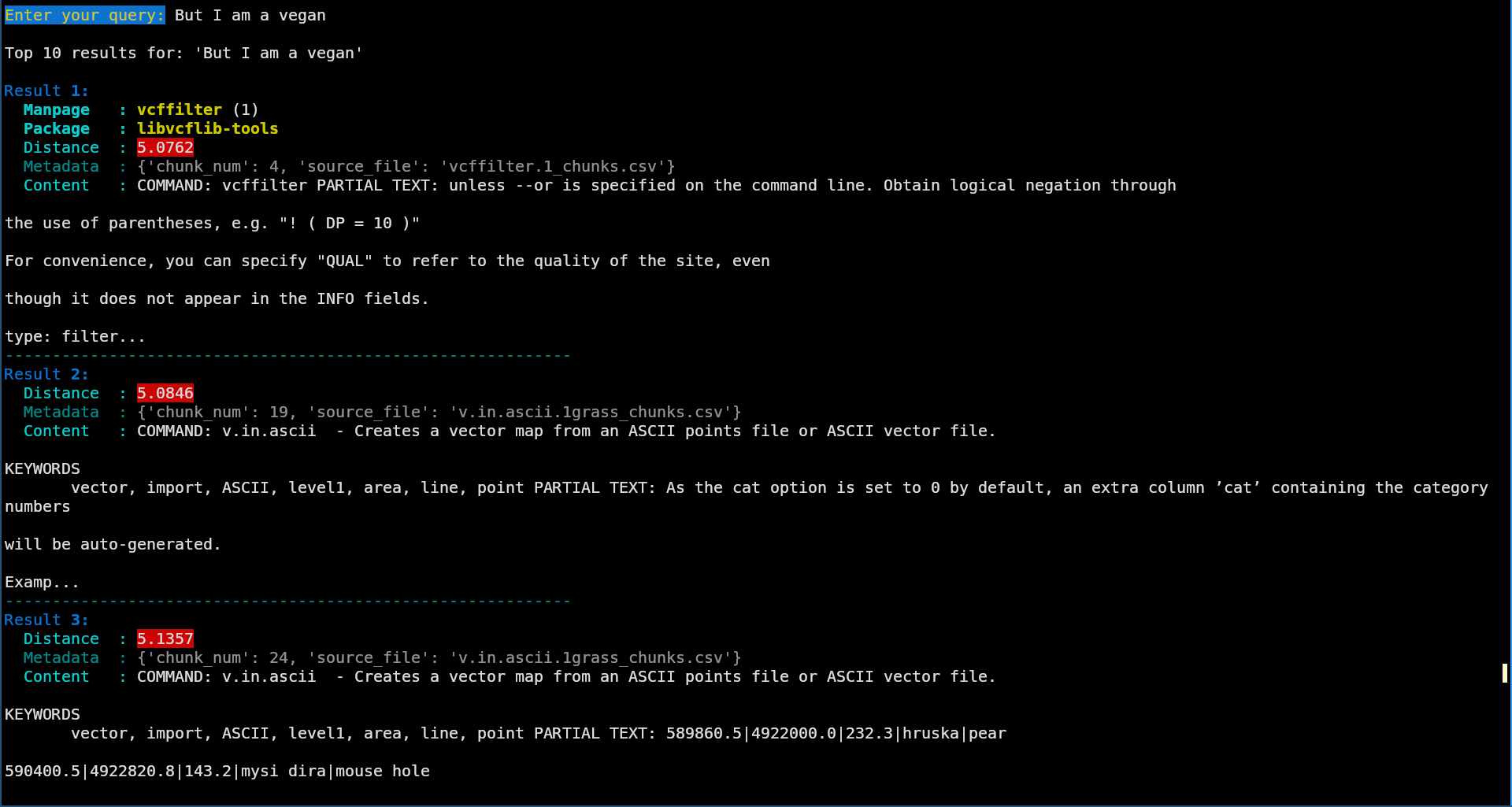
- But I am a vegan, going on with the silliness… Anyway, do take note that, although it is not directly relatable, the reported distance is very large, so the model does tell me in a way “these are my best results, but I wouldn’t trust them too much”.
- Who is the author of the Ruby manual?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
We were happy to present like this. During DebCamp, however, I was able to devote some time to translating my client into a Web-accessible system. Do note that it’s a bit brittle, and might break now and then. But you are welcome to play with it!
Play with the Web interface for our RAG for Debian manuals!
I find it worth sharing that, while we used quite a bit of GPU for the training (not too much — a couple of nights on an old-although-powerful nVidia 1070 card lent to us by the Felipe Esquivel Fund for Science and Cultural Support), all querying takes place in the CPU, and I usually get between 0.1 and 0.3 seconds per query. My server’s architecture is far from rock-solid, and it can break now and then… but at least it should respawn upon failure 😉 And it should at least be available there for a couple of weeks into August.
Anyway, this has been a very interesting journey getting my toes wet in the waters of LLM, and while current results are a bit crude, I think this can be made into an interesting tool for Debian exploration.